
Yielding accessors in Swift
Edit: The post previsouly said yielding accessors were available only in nightly toolchains, but
_readand_modifyare also available in release Swift builds; they’re just _ prefixed to signify they are work-in-progress.
It seems that Swift 5.6 is shaping up to a great iteration of the language and will bring a round improvements to performance-critical Swift code.
I was reading through a pitch by Joe Groff on some improvements to ARC and ownership the other day when I noticed that he mentions that accessor coroutines are available in Swift trunk.
I remember coroutines and generators being in discussion some time ago but I honestly had the impression the new Swift Concurrency solved most of the problems coroutines address. For this post I used the latest available toolchain Jan 9, 2022 nightly and gave accessor coroutines a quick try in Xcode.
The yield keyword
This whole article is based on Joe Groff’s read and modify section in his pitch — I just expanded a little the context with a more practical example and put a perspective on the performance implications.
Coroutines, generally, allow a function to yield execution in order to participate in cooperative multitasking and also to be able to return a value mutliple times. In other langauges you’d use a yield operator somewhat like a return but the function body could possibly continue execution after it.
All of this sounds a bit like how tasks and async sequences work in Swift right now. In fact, here’s an excerpt from an async iterator implemented in C# using yield to asynchronously return the sequence values:
|
|
But let’s get back to Swift!
In the pitch Joe mentions that a cool effect from using yield is that the function retains ownership over the returned value so it could safely provide in-place mutation of value-semantic data.
Let’s look at the expanded example from the pitch and what it all means.
Copy-on-write types and dynamic properties
In this article I’ll build a mock api request type for some app that sends data over to a web server. APIRequest features some useful methods like send(), dump() and more, and it holds an instance of Attachment which is a type wrapping a collection of bytes (the api request data):

The code for this model looks somewhat like that:
|
|
I’m initializing the attachment with roughly a megabyte of sample data.
Some of the constraints of my example model are that the API users should not be able to modify the attachment encoding property but should be able to freely manipulate bytes.
The quickest approach is to add a dynamic property to APIRequest which exposes Attachment.bytes while keeping the attachment property private:
|
|
This code doesn’t seem unreasonable — the code is simple and clear, and if you ever hardly use bytes it’s not likely to become an issue.
The detail here is that since the array is a copy-on-write type, returning the value out of the get accessor produces a copy if you want to mutate the result. E.g. appending a byte to the bytes property needs to, in fact, make a copy of the array, add the byte, and then assign it back to the property.
Let’s try this out in code! My app needs to create an api request and then, while processing some data, add a bunch of bytes to the attachment:
|
|
growAttachment(_) takes a request and adds a byte to it — I’ll call this method several times as my app process some dynamic input.
Note: Again, some of these APIs are a bit artificial but I’m trying to showcase the problem in the least possible amount of code.
To test this setup, I’ll add a loop to call growAttachment() repeatedly like so:
|
|
Firing up my favorite dev-tool Instruments, I can’t but notice some chilling memory usage numbers:

The memory usage is a little over two megabytes throughout the program execution. You only hold two copies of attachment at a time because the copying is performed serially — the memory is released before making a new copy for the next mutation.
However, the sum of all allocations is over 180Gb — this is all the memory in-flux during the execution as you make copies on-the-fly.
Yielding accessors
Now let’s try the same setup with the work-in-progress _read and _modify yielding accessors (only available in the nightly toolchains).
As in Joe’s example — I’ll use a single yield to return values but retain ownership to allow mutation in-place:
|
|
Note how the _modify accessor returns a reference to attachment.bytes. You don’t, however, need to do anything special when mutating the property. Treat it as any other property and the compiler will take care to automatically edit the value in-place.
Let’s give bytesRef a try:
|
|
growAttachmentRef(_) is identical to growAttachment(_) with the single difference that it uses bytesRef instead of bytes. To test this new function, I run a loop calling it the same amount of times as for growAttachment(_).
Profiling this new code in Instruments paints a different picture:

_modify allows the runtime to safely modify the bytes array in place and there is no need to copy the memory around for each mutation.
Performance benefits
You might be asking why is this important since the actual memory usage is about the same as you anyways need only two copies of the array in memory at a time.
Copying values takes time… As I said in the beginning, if you hardly ever mutate bytes the initial approach might be just fine for you. However, in the given example where I mutate the array 100, 000 times it really makes a difference if you copy memory for each call to append() or edit the value in-place.
I added some logging to the code and plotted the duration for the two identical operations over bytes and bytesRef in Instruments. The "By copy" region is the duration of the initial solution followed by the "By ref" which is the duration of the yield code (I added an arrow so you can see it):

In fact, let’s look at the tabular view to grok what the exact difference is:
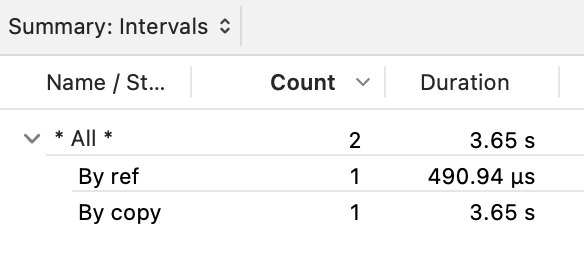
I mean… it’s not fair comparing the two anyways (since the latter doesn’t do any memory copying) but I’m trying to make the point that a seemingly innocent dynamic property added while budiling the data model might be a real performance hit.
Conclusion
The feature looks fairly polished and even features helpful diagnostics — for example when yield is missing you get this in Xcode:

Joe writes that read and modify are already implemented in the compiler (as I got to experience first hand with the nightly build) and the standard library has, and I quote, “experimented extensively with these features” and the team sees great value in adopting them.
All in all, I hope this will land in Swift 5.6, if not earlier, so we can use it in production code.
Where to go from here?
If you’d like to support me, get my book on Swift Concurrency:
Interested in discussing the new async/await Swift syntax and concurrency? Hit me up on twitter at https://twitter.com/icanzilb.

