
Optimization in Swift, part 3
In Part 2 I wrote about trying to optimize a very tight filter function with async/await. This helped when the filter performs some heavy work for each of the collection elements but not with my initial fictional use case (all about the test setup you can find out in Part 1).
Taking to the Standard Library
Since I already know that I’m not going to keep pushing the async/await variant of the code, I think it’s a good idea to look into the standard library. It often offers a specialized version of more common APIs to better suite a given use case.
Looking at the performance chart when filtering with Array.filter(_:), I’m noticing these strange peaks at certain sizes of the collection:
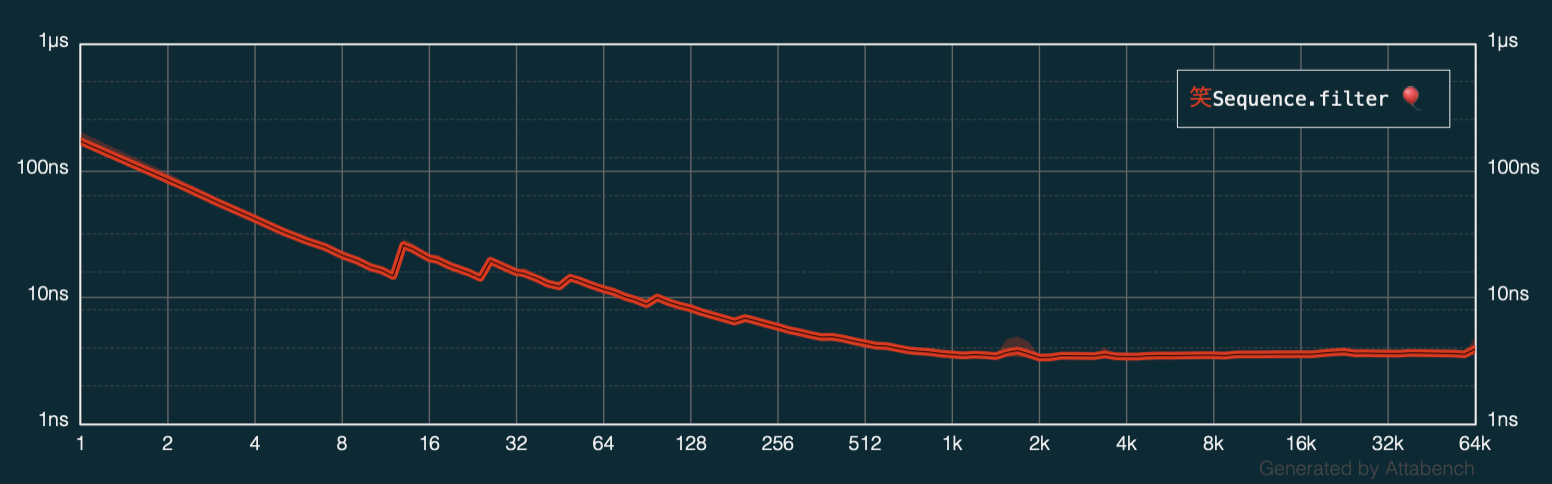
I wonder if these might be related to certain sizes of the array storage in memory? Array dynamically increases its storage as it grows so while producing filter’s result this might be affecting the performance.
Let’s use one of the standard library APIs to reserve the array capacity in advance, before populating it with data, and see if there is improvement.
Array.init(unsafeUninitializedCapacity:initializingWith:) allows me to reserve a buffer in memory and then populate it with the array’s data.
I’m going to use this API to see if I can avoid performance artifacts related to the array size like so:
|
|
I’m reserving a buffer in memory with the size of the original collection, then filter the original collection with filterLight(_:) and write the passing elements to the buffer. Finally, updating initializedCount sets the length of the resulting collection (because the result can contain less elements that the buffer you initially reserved).
This seems pretty straightforward so let’s fire up Attabench and see how it fares against the original code and the async/await version.
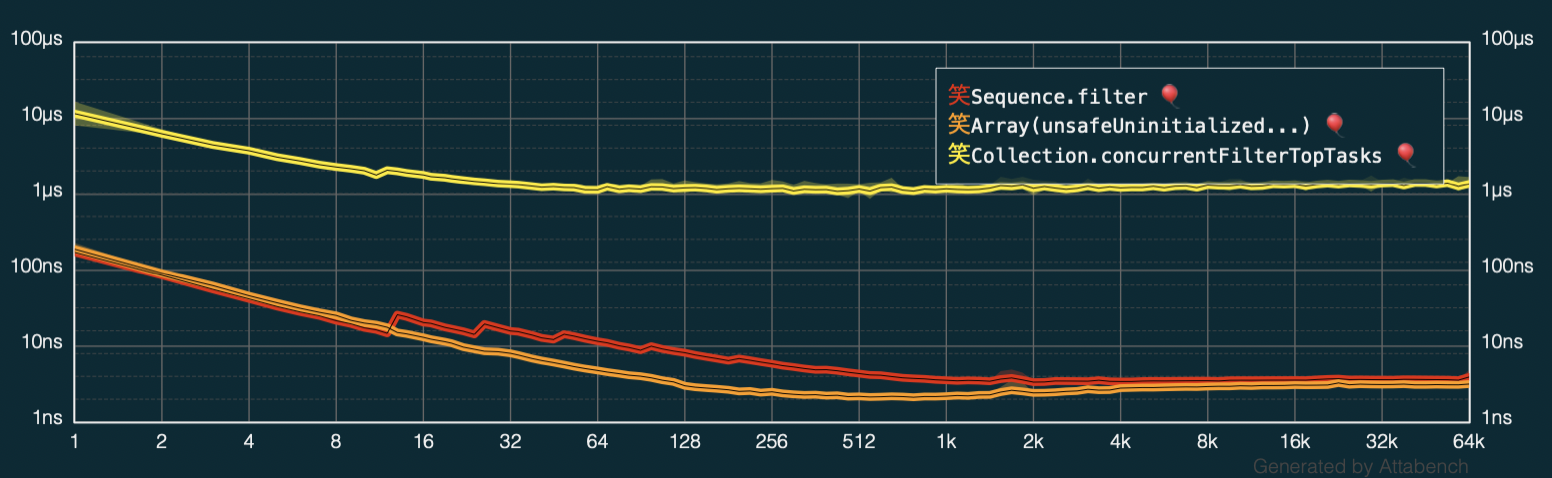
Aha! It seems like the latest code beats all previous versions and it doesn’t exhibit the performance degradation at certain collection sizes either.
I wonder though if this code is considerably more performant? In other words, is it a worthy iteration in the optimization process to keep developing onto?
Let’s disable the logarithmic scaling in Attabench to see how does performance actually fare comparing Array.filter and Array.init(unsafe...)
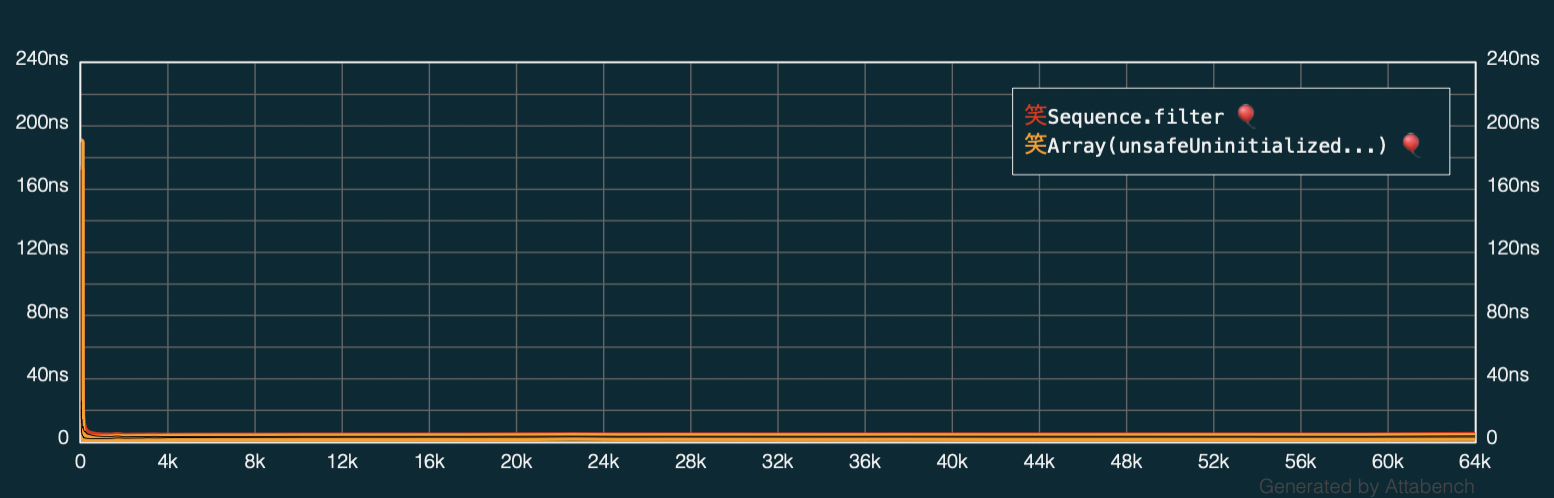
While there is a clear improvement, I’d say it’s rather negligable.
At this point I think that it doesn’t make much sense to keep grinding at optimizing something so simple as filterLight(_:)…
But what about filterHeavy(_:)? What if we have to perform some extra computations that allow for some tricks to get the work done faster?
I’ll replace filterLight with filterHeavy in the code from above and plot it against the code from my earlier posts.
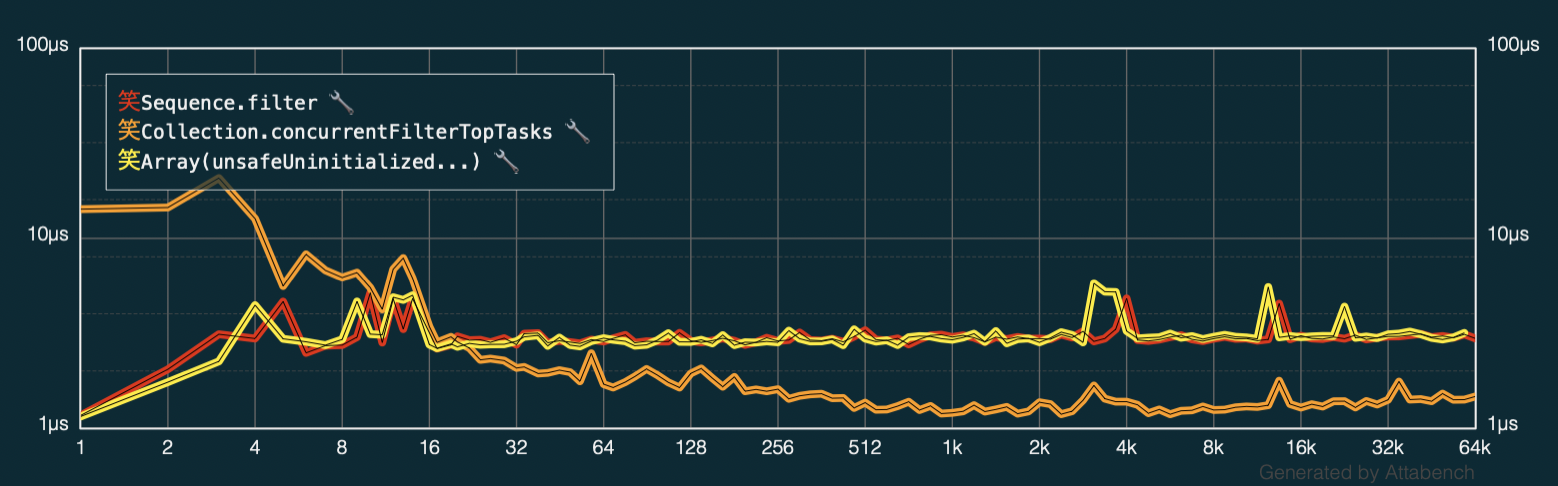
It seems that Array.init(unsafe... performs about the same as Array.filter(_:) so no much benefit peformance-wise…
However, looking at this chart — I think there might be a way to combine the benefits of using the unsafe buffer API and filtering concurrently. This should make the code faster than any of the three variants so far.
But that’s for me to look into next — in part 4 of the series.
Where to go from here?
If you’d like to support me, get my book on Swift Concurrency:
Interested in discussing the new async/await Swift syntax and concurrency? Hit me up on twitter at https://twitter.com/icanzilb.

