
Optimization in Swift, part 2
In Part 1 I wrote what this mini-series would be all about. Given the default array filtering is a performance bottleneck for my fictional app, I’m going to explore if I can write code that performs better in my specific use case.
In this part, I’m going to rewrite my initial filtering function and use the new async/await Swift concurrency syntax.
An async filter function
Since TaskGroup still has a performance issue in the current version of Swift, I’ll use a simplified code that uses only top tasks (e.g. no automatic cancellation, etc.).
I’m going to add a new function on Collection to asynchronously (and concurrently) filter the elements of the collection:
|
|
This function creates a loose bunch of top tasks, one for each of the collection’s items that run the filtering closure condition. I, then, return only the non-nil task values as the result collection.
This function doesn’t take care of cancellation but as a starting point — it’ll do.
As a filter closure I’m using the same function as in the previous part of this blog series:
|
|
Let’s run Attabench to find out how much faster this code is — I’m plotting my original filter code (in red) against the new async/await code (orange):
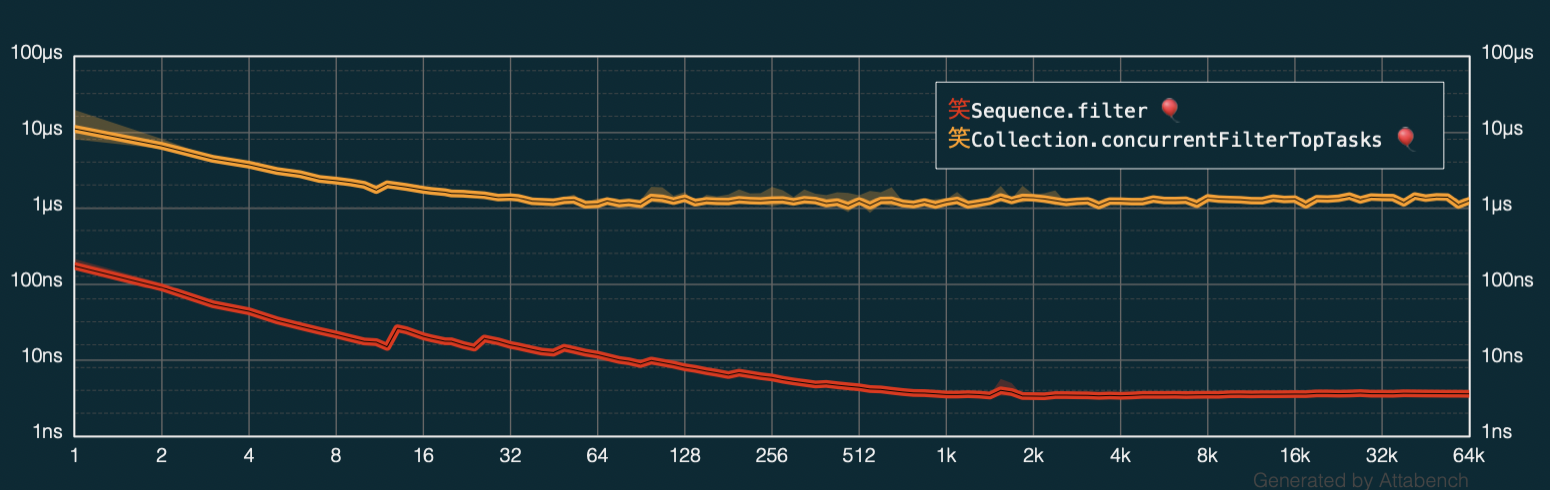
If you have any doubts — on this chart higher means slower (or less performant for the metric I want to optimize for). This actually makes sense — since the filtering code itself is so, so simple: num % 6 == 0, it makes no sense to spread this work over multiple CPU cores.
The time it takes to switch the execution across multiple threads and getting back the results incurs higher cost than executing the code itself. In other words the overhead of going concurrent is so high compared to the actual work that it makes no sense to use async/await here.
This is a common sentiment when people talk about concurrency — you have to add concurrency when you benefit from doing that.
Concurrency overhead
So when does it make sense to add concurrency? When the overhead of doing so is miniscule in comparisson to the kind of work you need to perform.
Let’s check out an example where it actually makes sense to use the async/await variant of the code.
Let’s use a function that does some heavier calculations instead of a simple math operation; I’ll use a new function called filterHeavy(_:):
|
|
This code is somewhat arbitrary but it gives me some well varied computation work that computes SHA checksums.
Let’s run again Attabench with the original code using Array.filter (in red) and the async/await version (in orange) and compare the results:
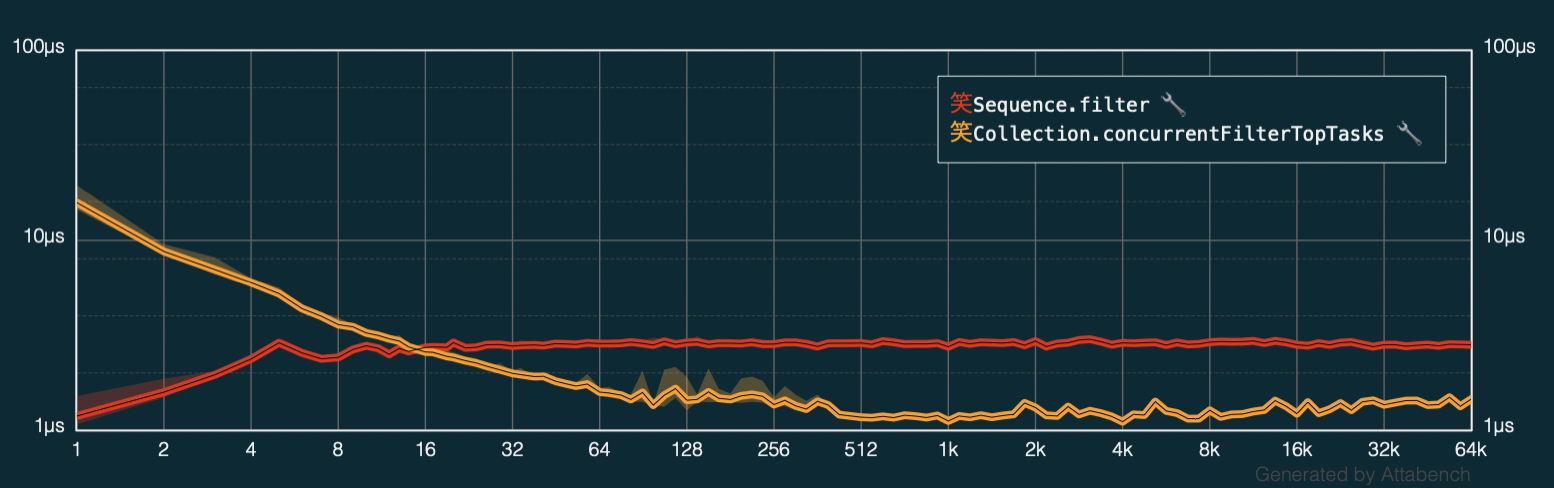
This paints a completely different picture than before when I did very light computation while filtering the collections.
You can see that the async/await code performs somewhat slower for very small collections (while it still pays the cost for spreading over multiple cores) but as soon as I’m working with more than 16 array elements I start reaping the concurrency benefits.
So, all of this makes a lot of sense — if you’re doing simple work, do it on one core so you don’t slow down your app by adding concurrency overhead. If you do work that is much heavier than switching threads — concurrency makes a difference.
What are good candidate tasks to do concurently? Encoding and decoding JSON, images or other data, processing data collections that requires some heavier work, image processing, etc.
So, for this series I’ll keep looking at my two examples filterLight and filterHeavy and compare what are the results and what makes sense in the optimization process.
In part 3 I’ll review some of the standard library APIs that I have in mind that could eventually help me build a faster filter. See you then — let me know if that’s been interesting so far!
Where to go from here?
If you’d like to support me, get my book on Swift Concurrency:
Interested in discussing the new async/await Swift syntax and concurrency? Hit me up on twitter at https://twitter.com/icanzilb.

